

spark在批处理和机器学习中有广泛的应用,下面让我们来逐个讲解spark相关的组件。
弹性分布式数据集
首先,RDD 作为 Spark 对于分布式数据模型的抽象,是构建 Spark 分布式内存计算引擎的基石。很多 Spark 核心概念与核心组件,如 DAG 和调度系统都衍生自 RDD。
其次,尽管 RDD API 使用频率越来越低,绝大多数人也都已经习惯于 DataFrame 和Dataset API,但是,无论采用哪种 API 或是哪种开发语言,你的应用在 Spark 内部最终都会转化为 RDD 之上的分布式计算。
RDD 的核心特征和属性
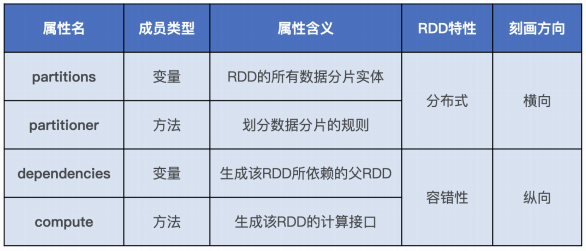
RDD 具有 4 大属性,分别是 partitions、partitioner、dependencies 和 compute 属性。正因为有了这 4 大属性的存在,让 RDD 具有分布式和容错性这两大最突出的特性。
Stage 内部的流水线式计算模式
在 Spark 中,内存计算有两层含义:第一层含义就是众所周知的分布式数据缓存,第二层含义是 Stage 内的流水线式计算模式。
在计算过程中,一个个rdd连接起来构成一个DAG图,这个DAG顶点是一个个 RDD,边则是 RDD 之间通过 dependencies 属性构成的父子关系。
Stages 的划分
DAG 毕竟只是一张流程图,Spark 需要把这张流程图转化成分布式任务,才能充分利用分布式集群并行计算的优势。用一句话来概括从 DAG 到 Stages 的转化过程,那应该是:以 Actions 算子为起点,从后向前回溯 DAG,以 Shuffle 操作为边界去划分 Stages
Stage 中的内存计算
在 Spark 中,流水线计算模式指的是:在同一 Stage 内部,所有算子融合为一个函数,Stage 的输出结果由这个函数一次性作用在输入数据集而产生。
调度系统
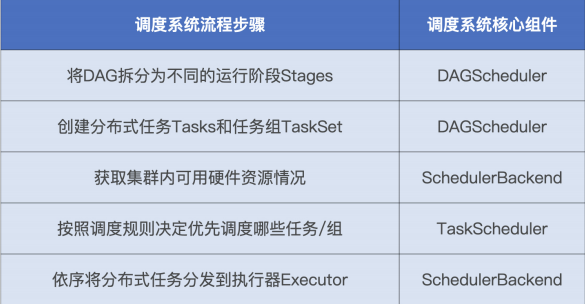
spark调度系统包含 3 个核心组件,分别是 DAGScheduler、TaskScheduler 和SchedulerBackend。这 3 个组件都运行在 Driver 进程中,它们通力合作将用户构建的DAG 转化为分布式任务,再把这些任务分发给集群中的 Executors 去执行。
调度流程
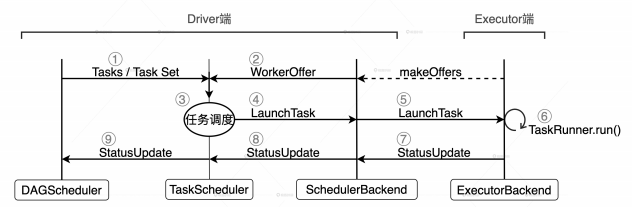
TaskScheduler 的核心是任务调度的规则和策略,TaskScheduler 的调度策略分为两个层次,一个是不同 Stages 之间的调度优先级,一个是 Stages 内不同任务之间的调度优先级
对于这种 Stages 之间的任务调度,TaskScheduler 提供了 2 种调度模式,分别是FIFO(先到先得)和 FAIR(公平调度)
当 TaskScheduler 接收到来自
SchedulerBackend 的 WorkerOffer 后,TaskScheduler 会优先挑选那些满足本地性级别要求的任务进行分发。众所周知,本地性级别有 4 种:Process local < Node local< Rack local < Any。从左到右分别是进程本地性、节点本地性、机架本地性和跨机架本地性。从左到右,计算任务访问所需数据的效率越来越差。
Spark 调度系统的原则是尽可能地让数据呆在原地、保持不动,同时尽可能地把承载计算任务的代码分发到离数据最近的地方,从而最大限度地降低分布式系统中的网络开销
存储系统
存储系统的服务对象,分别是 RDD 缓存、Shuffle 和广播变量。
RDD 缓存:一些计算成本和访问频率较高的 RDD,可以以缓存的形式物化到内存或磁盘中。这样一来,既可以避免 DAG 频繁回溯的计算开销,也能有效提升端到端的执行性能
Shuffle:Shuffle 中间文件的位置信息,都是由 Spark 存储系统保存并维护的,没有存储系统,Shuffle 是玩不转的。Spark 默认采用 SortShuffleManager 来管理 Stages 间的数据分发,在 Shuffle write过程中,有 3 类结果文件:temp_shuffle_XXX、shuffle_XXX.data 和shuffle_XXX.index。Data 文件存储分区数据,它是由 temp 文件合并而来的,而 index文件记录 data 文件内不同分区的偏移地址。Shuffle 中间文件具体指的就是 data 文件和index 文件,temp 文件作为暂存盘文件最终会被删除。
广播变量:利用存储系统,广播变量可以在 Executors 进程范畴内保存全量数据,让任务以 Process local 的本地性级别,来共享广播变量中携带的全量数据。
存储系统组件
MemoryStore 用来管理数据在内存中的存取,DiskStore 用来管理数据在磁盘中的存取。对于存储系统的 3 个服务对象来说,广播变量由 MemoryStore 管理,Shuffle 中间文件的落盘和访问要经由 DiskStore,而 RDD 缓存因为会同时支持内存缓存和磁盘缓存两种模式,所以两种组件都有可能用到。
内存管理
在管理方式上,Spark 会区分堆内内存(On-heap Memory)和堆外内存(Off-heapMemory)。这里的“堆”指的是 JVM Heap,因此堆内内存实际上就是 Executor JVM的堆内存;堆外内存指的是通过 Java Unsafe API,像 C++ 那样直接从操作系统中申请和释放内存空间。其中,堆内内存的申请与释放统一由 JVM 代劳。比如说,Spark 需要内存来实例化对象,JVM 负责从堆内分配空间并创建对象,然后把对象的引用返回,最后由 Spark 保存引用,同时记录内存消耗。反过来也是一样,Spark 申请删除对象会同时记录可用内存,JVM 负责把这样的对象标记为“待删除”,然后再通过垃圾回收(Garbage Collection,GC)机制将对象清除并真正释放内存。
内存划分
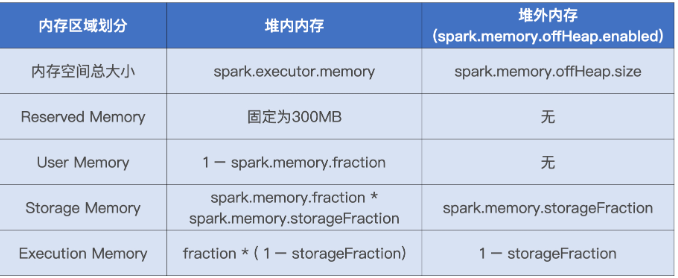
内存管理
在 1.6 版本之后,Spark 推出了统一内存管理模式。统一内存管理指的是 Execution Memory 和 Storage Memory 之间可以相互转化。其中Execution Memory用于执行分布式任务,如 Shuffle、Sort 和 Aggregate 等操作,Storage Memory用于缓存 RDD 和广播变量等数据。
转换规则
如果对方的内存空间有空闲,那么双方都可以抢占;
对 RDD 缓存任务抢占的执行内存,当执行任务有内存需要时,RDD 缓存任务必须立即归还抢占的内存,其中涉及的 RDD 缓存数据要么落盘、要么清除;
对分布式计算任务抢占的 Storage Memory 内存空间,即便 RDD 缓存任务有收回内存的需要,也要等到任务执行完毕才能释放。
spark优化捷径
开启AQE,使用DataFrame 或是 Dataset API 进行开发
AQE 可以让 Spark 在运行时的不同阶段,结合实时的运行时状态,周期性地动态调整前面的逻辑计划,然后根据再优化的逻辑计划,重新选定最优的物理计划,从而调整运行时后续阶段的执行方式
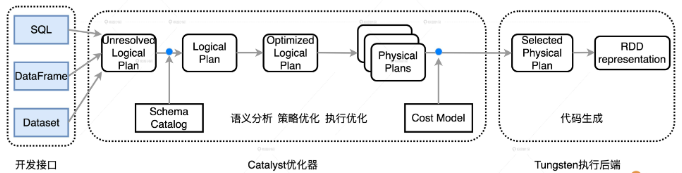
在数据结构方面,Tungsten 自定义了紧凑的二进制格式。它天然地避免了 Java 对象序列化与反序列化引入的计算开销。
Tungsten 利用 Java Unsafe API 开辟堆外(Off HeapMemory)内存来管理对象。堆外内存有两个天然的优势:一是对于内存占用的估算更精确,二来不需要像 JVM Heap 那样反复执行垃圾回收。
在运行时,Tungsten 用全阶段代码生成(Whol Stage Code Generation)取代火山迭代模型,这不仅可以减少虚函数调用和降低内存访问频率,还能提升 CPU cache 命中率,做到大幅压缩 CPU idle 时间,从而提升 CPU 利用率。
能省则省、能拖则拖
尽量把能节省数据扫描量和数据处理量的操作往前推;
尽力消灭掉 Shuffle,省去数据落盘与分发的开销;
如果不能干掉 Shuffle,尽可能地把涉及 Shuffle 的操作拖到最后去执行。

评论区